This article was originally published on DevOps.com.
Monitoring versus observability is a hotly debated topic. It’s been argued that they’re two distinct things — the former just a high-level overview of a problem after the fact, while the latter enables you to be proactive. Observability has also been dismissed as jargon, much how “DevOps” sounds to the seasoned operator.
The thing is, the whole debate misses the point: it’s not monitoring versus observability – the two are not mutually exclusive, but symbiotic. Like the Ouroboros — the ancient Egyptian symbol of a snake eating itself — monitoring and observability both feed each other. Monitoring tells you what’s broken and where you need to have a higher degree of visibility. In other words, if something is broken and you’re having difficulty telling why, you need to increase visibility (i.e., by adding more checks and instrumentation). The same can be said for observability — a term used to describe telemetry, event logging, and trace data (and, it can be argued, in many ways a subcategory of the traditional sense of performance monitoring). Observability gives you the richest context but the difficulty is in understanding the holistic view — AKA, where to look next. Say your observability tool shows 99th percentile latency and you see a huge uptick: you have to guess as to why there’s such an increase. Based on your own operator knowledge, it’s either the network introducing the latency or the database is unable to respond in a reasonable or consistent time — for example, the disk could be slow or you’re on a multi-tenant system and someone is consuming CPU time.

The difference with monitoring in this scenario is it would let you know that you exceeded your trend on latency, therefore something has gone awry. It’s the same path, but you still have to make logical jumps based on your own experience — unless you’ve gone ahead and contextualized these from the get-go by creating runbooks and checklists for certain failure scenarios. If a monitoring check is properly created it will provide guidance as to what to look at first, then the observability tool gives you the much lower-level insight to go through each of those prescribed steps. Another way to look at it is monitoring is step 1 and observability is step 2. In this way, you can see how monitoring and observability feed each other, rather than existing as wholly separate concepts or toolsets.
It all comes down to context. Traditional tools for monitoring and observability encompass everything from traditional logging to telemetry data, but none of that matters unless you have context as to why a certain behavior is happening. With this traditional approach, your users become your monitoring – tweeting at you when your site is down — and that’s bad for business. You’re still going to have to guess the context, spelunking through a multitude of data points to figure out what went wrong. It’s a polarizing topic — perhaps not quite as polarizing as monitoring versus observability — but there is such a thing as too much data. My experience has taught me that a curated approach to monitoring and observability makes better use of resources and helps combat alert fatigue.
Context is key. Monitoring is the “What is down?” and the context that helps lead you to determine your “Why?”. Observability tooling lets you dig further into those whys. A modern solution needs to go beyond just alerts to offer rich context and actionable insight.
Pairing monitoring best practices with an effective observability solution can both tell you something is wrong and offer rich context. You get to the why faster, making it easier to arrive at the right conclusions in a timely fashion. One approach that marries the concepts of monitoring and observability is to apply workflow automation principles to monitoring. Operators need to have the tools to automate their monitoring workflows (like auto-remediation), and reserve alerts for complex tasks that can’t be automated.
By laying aside the debate of monitoring or observability and acknowledging the ways in which they feed each other, operators can have a holistic view and deep context into their systems — ultimately improving their workflows and offering better end-user experiences.
Related Posts

Challenges of big infrastructure monitoring
The hodgepodge of technologies brings even more challenges when we’re talking about big infrastructure. In this post, Sensu CTO Sean Porter discusses.

Heightened visibility & deeper control with a monitoring control plane
The control plane is a centralized management interface. In this post, Caleb discusses the role of a control plane in monitoring — telling the story of how our users’ need for deep visibility into their applications, and control over their monitoring.
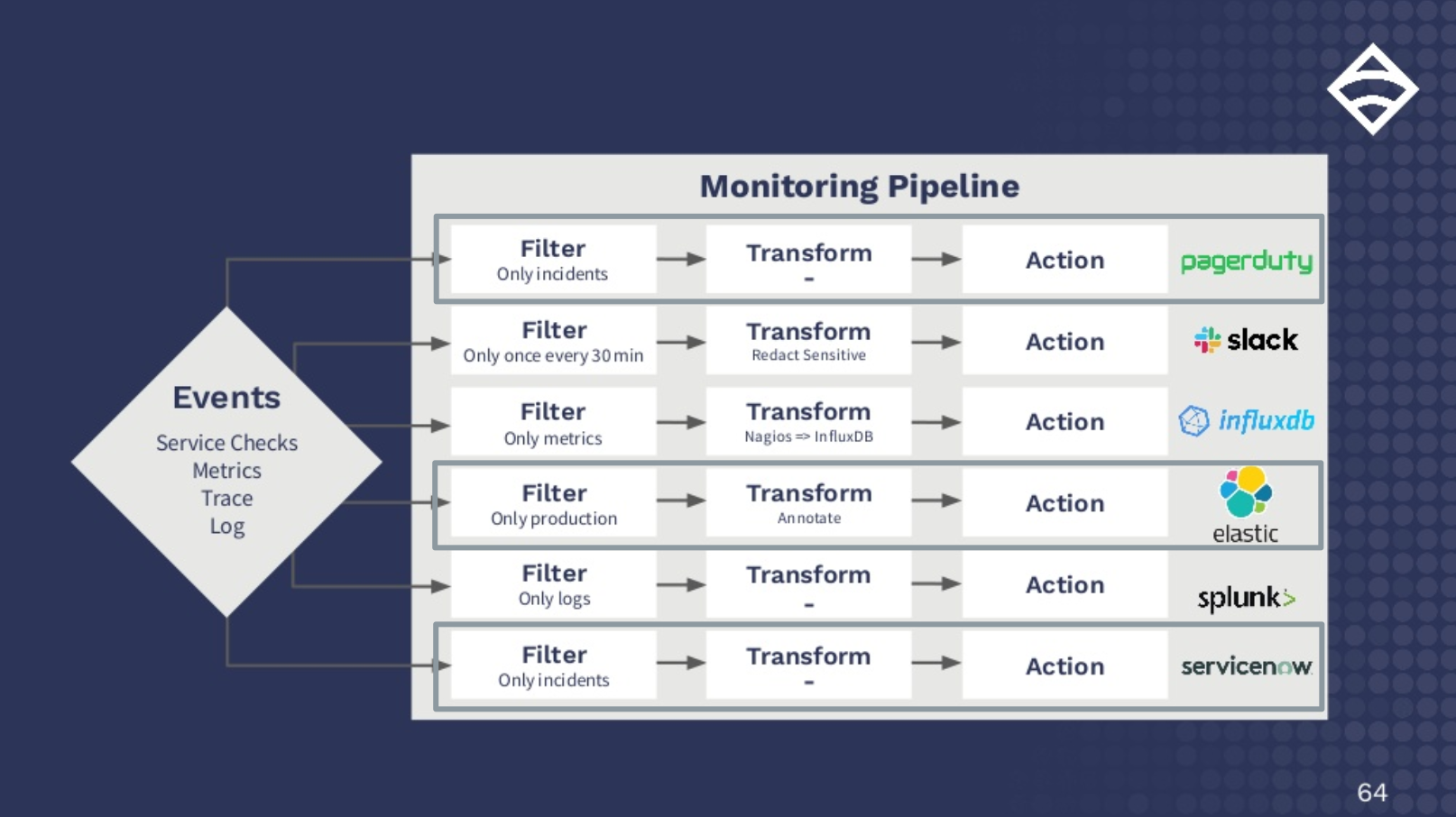
Observability Pipelines: Why you need one, and why you should stop rolling your own
Why you should be using Sensu’s observability pipeline — and why rolling your own solution from scratch is far too costly."> <meta name="generator

Made with #monitoringlove by SensuTM in Canada 🇨🇦 and the USA 🇺🇸. © 2017-2021 – Privacy Statement – Terms & Conditions