At Monitorama 2018, Engineering Manager Kale Stedman shared Demonware’s journey to assisted remediation, or as he likes to call it: “How my team nearly built an auto-remediation system before we realized we never actually wanted one in the first place.”
In this post, I’ll recap Kale’s Monitorama talk, highlighting the key decisions that helped his team reduce daily alerts, fix underlying problems, and establish a more engaged Monitoring Team — including the steps they took to migrate over 100K services from Nagios to Sensu.
Scale and complexity at Demonware
As part of the entertainment company Activision Blizzard, Demonware creates and hosts the online services for video games like the Call of Duty series, Guitar Hero, Skylanders, and hundreds of others across platforms like PlayStation 4, Xbox One, Nintendo Switch, and more. These games are a collection of services that spans thousands of nodes and supports 469+ million gamers.

As Kale notes, every game behaves differently based on the console it’s on, so there’s a whole lot of complexity in terms of what they have to monitor. Naturally, they want to limit outages or interruptions that affect their gamers.
Kale joined Demonware as an SRE in 2012 (which made him “six Call of Duties old” at the time of his talk), and became engineering manager of the NOC team in 2015.
Before: CRIT, all the time, every day
As Kale puts it, the realities the NOC team dealt with “sucked." Given the scale and complexity, their Nagios setup returned thousands of critical errors, “basically all the time, every day.”
It was a “lose-lose situation” because the team not only had to make sense of a “sea of alerts” and “very cryptic outputs,” but also struggled to understand the impact to gamers and when to escalate issues to SREs.
Team morale was understandably low, turnover was high, and team members weren’t engaged in their work.
Kale approached Demonware’s senior leadership team and told them something had to change; they were open to a new direction as long as the team maintained their SLAs. This gave Kale the greenlight (and greenfield!) he needed to put a plan in place.
The challenge: get out from under a mountain of alerts and introduce a sustainable monitoring and auto-remediation system
The first step was to rebrand the team and “think outside the NOC.” They renamed themselves the Monitoring Team, determined to no longer play a “whack-a-mole” style of monitoring and remediation.
Rather, they’d build an auto-remediation tool with the following layers:
- Detection: To check that things are working the way they’re supposed to and alert when they’re not.
- Decision: To process the alert, validate it, and decide what remediation to run.
- Remediation: To run the remediation step, and generate a successful check.
And so they got started with the detection layer, which meant replacing Nagios.

Migration from Nagios to Sensu
As the team looked for a Nagios replacement, their main requirement was “not Nagios,” Kale says. They researched other monitoring platforms, and determined Sensu to be the obvious choice because it supports Nagios checks out of the box; supports custom attributes, filters, and handlers; and is designed for scalability.
Still, the migration was a daunting task based on sheer volume: the team had well over 100K service checks across five different Nagios instances. So, they approached the migration in phases. First, they migrated all base system checks (load averages, CPU, memory, etc.), which left them with 60,000 service checks. Next, they handled the most common checks (based on the amount of systems they were deployed to), bringing them to 40,000 services, and then dealt with some 10,000 repeat offenders (any checks that alerted over and over).
With 30,000 Nagios service checks left, they decided to review them one by one. Although time consuming, it felt like the most practical way forward; it helped them end a tradition of low-quality processes, and figure out which alerts truly required attention.
Kale says it was huge mindset shift for his team. Now, there’s “no such thing as an ‘OK’ alert.” The purpose of generating an alert is to provide information about something the team cares about, and every single alert requires follow up. Kale says, “It seems kind of obvious, but we had been focusing for so long on the alerts that we’d forgotten that they’re indicative of actual problems underneath.”
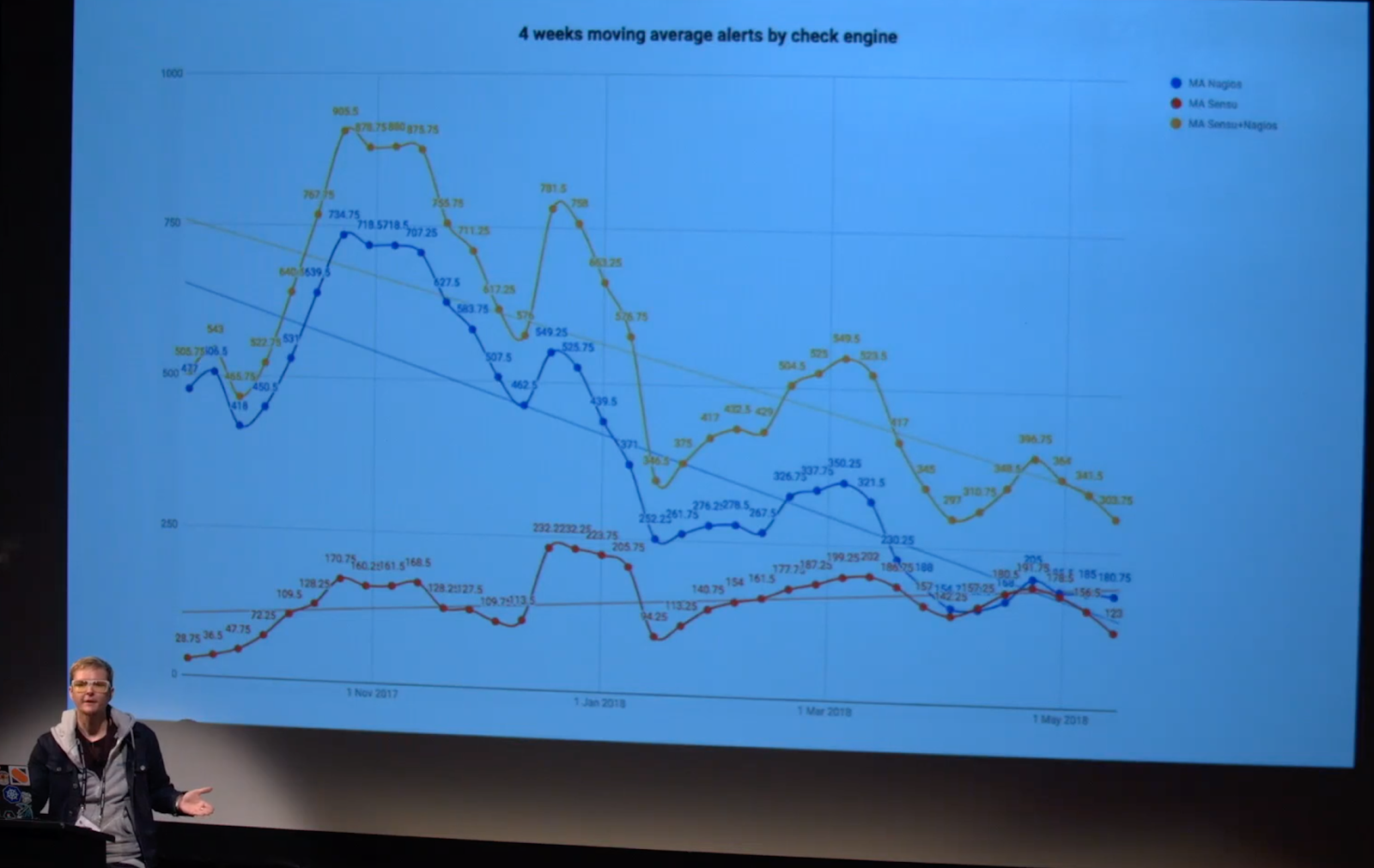 This slide shows the change in the daily volume of alerts (represented in a four-week moving average to smooth out the data a bit) with the total alert volume in goldenrod, the Nagios volume in blue, and the Sensu volume in red.
This slide shows the change in the daily volume of alerts (represented in a four-week moving average to smooth out the data a bit) with the total alert volume in goldenrod, the Nagios volume in blue, and the Sensu volume in red.
Next, the team worked on the decision layer of their tool, utilizing StackStorm, which bills itself as IFTTT (if this, then that) for Ops. Essentially, StackStorm is a simple rules engine that allowed the team to take a trigger from an event, run it against criteria they determined, and then run actions — so they could get very granular in terms of who received an alert based on its type, the systems it affected, time of day, and more.
Rethinking auto-remediation
Now that they’d built detection and decision layers, Kale says they were able to step back and reconsider their plan for the auto-remediation layer: “If we’re seeing so much success without an auto-remediation runner, why should we actually invest in that opportunity cost and development time and that potential risk?”
The team figured that humans are way better than computers at making fuzzy decisions based on uncertainty. Kale asks, “What if we use computers for what they’re good at, and humans for what they’re good at?”
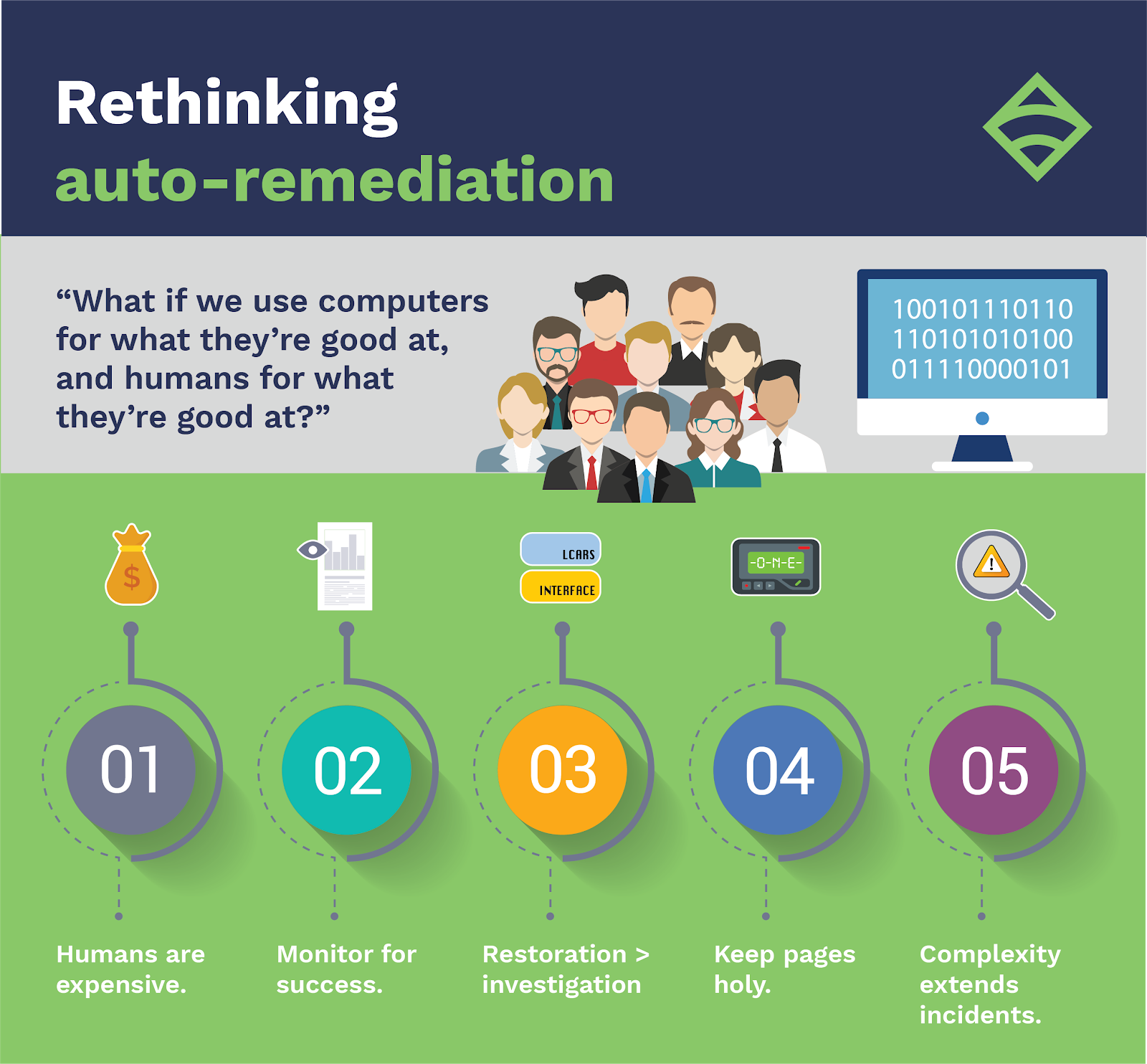
So they decided to build an assisted remediation platform — dubbed Razz — which would include the same detection and decision layers, and would add what they termed enrichment and escalation layers.
Kale explains that the new system was built around what they’ve come to think of as their monitoring maxims, which I’ve paraphrased and re-ordered below for brevity.
1. Humans are expensive.
The detection layer, powered by Sensu, allowed the team to trust the alerts they received. As Kale notes, humans are expensive, and it isn’t worth their time to weed through a bunch of potentially false or unactionable alerts. Sensu checks streamlined the process so that team members receive alerts about validated problems that need attention.
On the flip side, humans are also expensive because they’re creative, unpredictable, and inconsistent. In short, people make mistakes. So it would be more valuable to automate checks with Sensu and limit manual, error-prone processes, thereby freeing people up to fix problems instead of inadvertently creating them.
2. Monitor for success.
The decision layer of Razz, utilizing StackStorm, meant the right people were receiving the right alerts at the right time, which helped reduce noise and alert fatigue.
The team also took steps to aggregate related checks into a single check to reduce alert volume. Kale says, “We get a strong sense of the overall health of our system, not just a list of individual failures,” making it easier to take action.
3. Restoration > investigation.
Before Razz, the Monitoring Team found that when they escalated issues, SREs would lose time looking at various logs and dashboards, depending upon their areas of expertise and interest. And, time searching for what went wrong meant more downtime for gamers.
That’s why the team added an enrichment layer to Razz by leveraging StackStorm to create a widget system that allowed them to query additional data and add it to the alert object, generating a JIRA ticket for the SREs.
The enrichment layer was based on the LCARS system in Star Trek. In the show, LCARS displays a bunch of data about the ship’s systems relevant to the specific situation at hand that helps the captain make an immediate decision to secure a narrow escape. Similarly, Demonware’s LCARS system would pull in the necessary dashboards and logs, the important statuses of their consoles, etc. — all defined within the Sensu check — thus providing the context an SRE would need to make an informed decision.
4. Keep pages holy.
When designing the escalation layer of Razz, it was important for the team to keep pages holy.
Every time an SRE receives a page, it should be because they are the appropriate person to initiate remediation and make a decision about what to do.
5. Complexity extends incidents.
Throughout each step of the process, the team pushed back against complexity because the more complicated a check is, the more complicated the remediation is, and the more chance for human error.
“If we couldn’t understand what it meant when it alerted, it’s almost guaranteed we’re going to screw up somehow,” Kale says. So they reduced complexity at each step to help make decisions simple and as predictable as possible.
Live long and prosper
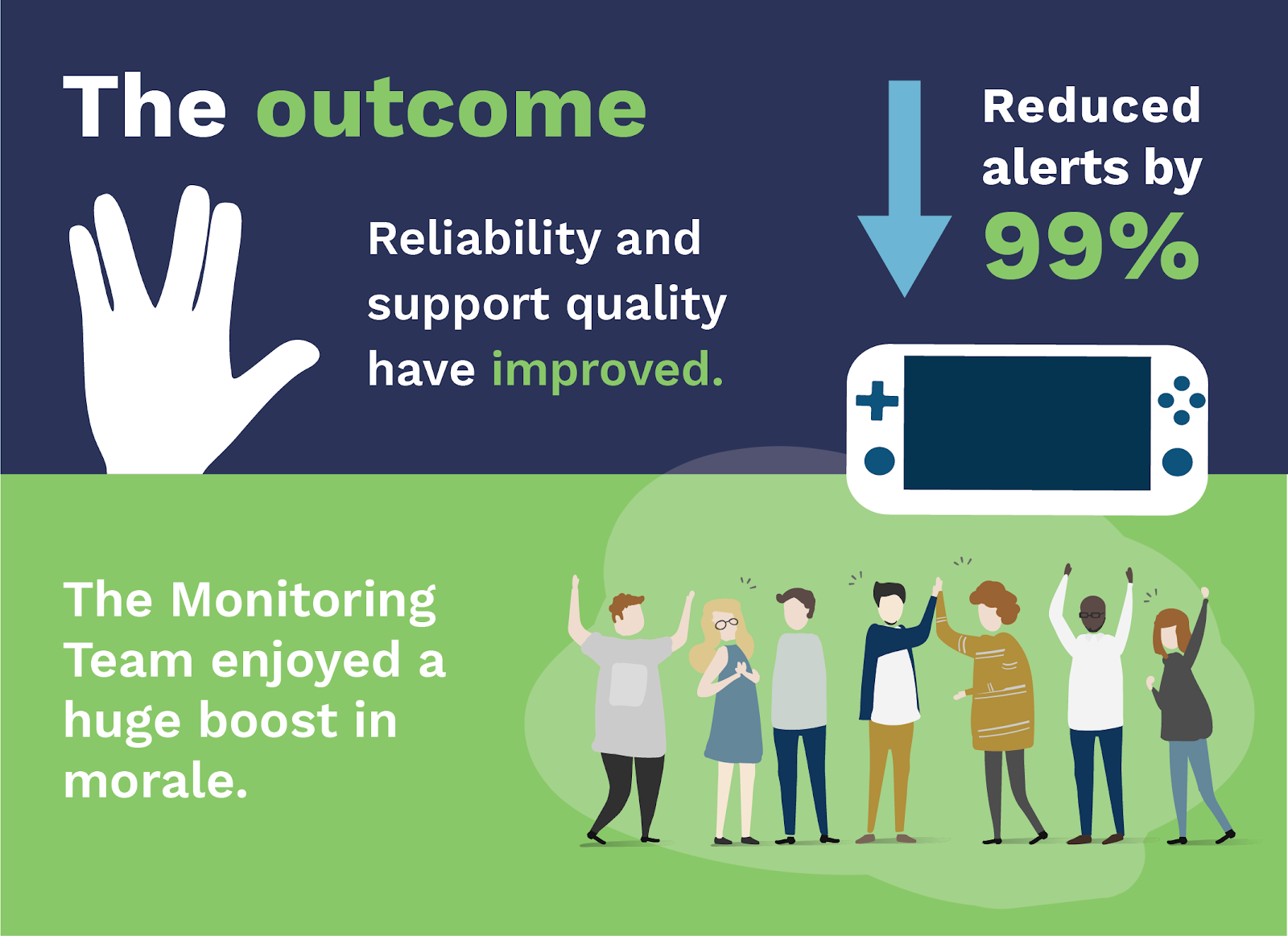
The outcomes of overhauling their alert system and remediation processes were dramatic:
- Alert volume reduced from thousands of alerts per day to tens of alerts per day. The team used to schedule sysadmins 24-7 to handle alerts; now they could scale back to a purely on-call model.
- Data-driven decisions became the norm. Since every alert is tracked in a JIRA ticket, every alert has an audit trail. This amounts to a ton of rich data about the failure as well as the response, which allows the team to dig into patterns and fix long-standing bugs.
- Reliability and support quality improved. As Kale says, “With more valuable, useful escalations routed to teams, they have better incentives and opportunities to make their services more reliable.”
- The Monitoring Team enjoyed a huge boost in morale. They’d put in a lot of time and work — they learned to code, learned how to use Docker, built a CI/CD pipeline, introduced unit testing, all while maintaining their SLAs — and it was hugely rewarding. Kale says, “Every single step of the way has improved the quality of life for everyone on the team … We’ve taken our careers to the next level.”
In the end, says Kale, Demonware “never built that auto-remediation system that we set out to build. We didn’t have to. Because we found out that by focusing on the humans, by making it easier to actually fix problems, it was a better solution anyway.”
Interested in reading more about auto remediation? Here’s an in-depth look at how to do auto remediation from our alert fatigue blog series.

Made with #monitoringlove by SensuTM in Canada 🇨🇦 and the USA 🇺🇸. © 2017-2021 – Privacy Statement – Terms & Conditions